Transforming Supply Chains: A Data-Driven Approach
- Bert Brijs

- Feb 10
- 3 min read
Updated: Apr 28
The Challenge: Disconnected Planning Across Boundaries
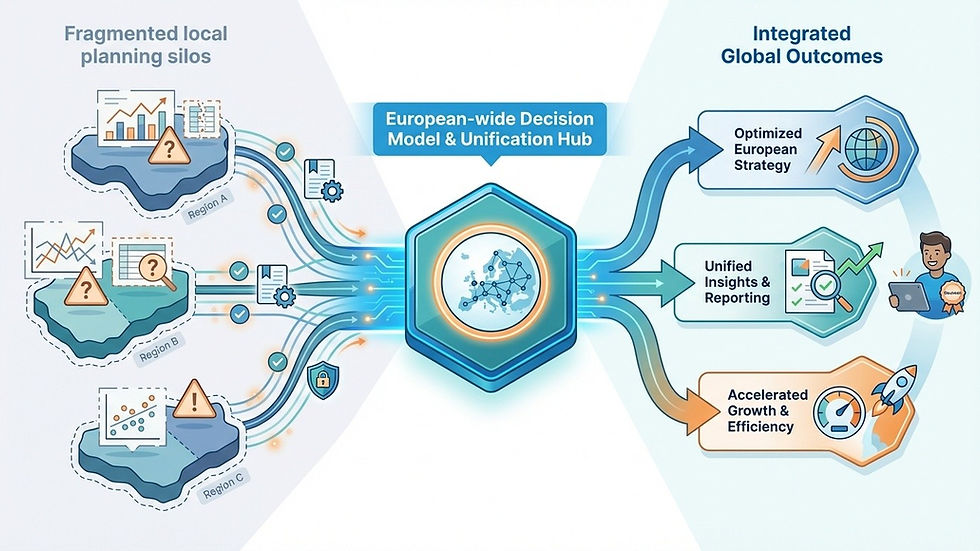
At project start, our client’s supply chain planning landscape was a patchwork of local forecasting tools, independent replenishment algorithms, disparate master production schedules, and region-specific purchasing requirements. Each operating unit had developed its own “version of the truth,” leading to:
Inconsistent forecasts with little ability to compare across regions.
Weak visibility into inventory and transfer requirements.
Manual reconciliation between local and European-level planning.
Limited governance on data definitions, quality, and ownership.
These are common symptoms of siloed data management in global organisations—supply chain systems that work independently but not collectively. The result? Slow response to demand shifts, sub-optimal production planning, and reduced leverage of supply chain data for decision-making.
Step 1: Establishing a Master Data Foundation
Integration can only succeed on the basis of shared definitions and trusted data. Our first task was to:
Inventory all relevant master data domains: customers, employees, suppliers, products, locations, lead times, bill of materials, planning hierarchies...
Identify data owners and stewards across business units to ensure accountability.
Define naming conventions and standards aligned with international norms such as ISO 8000 for data quality and master data exchange—critical when systems and processes span countries and functions.
This foundational work did more than enable system integration; it made the organisation conscious of the data dependencies underlying planning algorithms and forecasting models. Master data became not just a technical artefact but a business asset.

Step 2: Data Governance that Scales
Master data management without governance leads back to silos. We co-designed a data governance framework that touched people, processes, and technology:
A governance board with representation from operations, supply chain, IT, and finance.
Clear roles: data controllers, stewards, and subject matter experts.
Policies for data quality metrics, validation rules, and escalation paths.
With these structures in place, data definitions, quality checks, and ownership were standardised across regions. These mechanisms ensure that forecasts, replenishment parameters, and schedules are comparable, interoperable, and auditable. This aligns with best practices in supply chain governance, where clarity in data definitions and quality rules is a prerequisite for reliable decision-making.
Step 3: Data Mapping and Integration
The heart of the project was the technical integration layer: mapping local operational data into a harmonised European view. We approached this in three phases:
Semantic mapping of fields—aligning terms like “forecast,” “order point,” and “net requirements” across systems.
ETL pipelines—extracting source data, transforming it to the common model, and loading it into the integration platform.
Cross-system reconciliation and checks to ensure that master production schedules, transfers, and local forecasts feed reliably into European-level planning tools.
Mapping was not merely about matching fields; it involved reconciling business logic embedded in different replenishment and forecasting engines. This is a frequent blind spot in supply chain data work: two systems can have identical field names but very different interpretations. Our integration layer codified these business rules explicitly, reducing ambiguity and error.
Step 4: Embedding Quality and Feedback Loops
Integration is not a one-time exercise. As the new data flows went live, we embedded continuous quality controls:
Profiling dashboards to monitor data freshness and completeness.
Alerts for deviations in key metrics (e.g., forecast accuracy, lead time anomalies).
Regular governance checkpoints to refine definitions and address exceptions.
This mirrors academic and industry insights that effective supply chain data practices must extend beyond technology to organisational processes and roles.
Outcomes: From Fragmentation to Insight
By closing the gap between local planning silos and European-wide decision models, the organisation is on its way to achieve:
Consistent cross-region data views capable of supporting consolidated planning.
Fewer reconciliations and manual interventions during planning cycles.
Improved forecast reliability due to standardised definitions and data quality.
Faster scenario analysis for production and purchase requirements.
Perhaps more importantly, the engagement shifted the organisation’s mindset from “data as a by-product” to “data as an enabler.”
Key Takeaways
Start with definitions—without shared master data, integration efforts are brittle.
Governance is structural—not an add-on; it must sit alongside operational accountability.
Integration is as much about rules as data—mapping business logic unlocks true interoperability.
Quality never sleeps—continuous measurement and correction are essential to maintain trust.
Looking Ahead
For any multinational extending its planning footprint, a data management framework is not optional—it’s strategic. Lingua Franca’s involvement helped this client unlock a European-wide view of their supply chain that is both consistent and actionable. With governance, master data, and integration firmly embedded, the organisation is positioned to respond to market volatility with confidence.
If your supply chain struggles with consistency, visibility, or cross-system planning, a structured data management framework may be the key to achieving operational and strategic alignment.



Comments