Slowly Changing Dimensions with KNIME
- Bert Brijs

- Sep 19, 2025
- 2 min read
This is an extract from the book of our partner Marc Goossens "Building, loading and exploring a data warehouse with KNIME .a practical case" available on Amazon via this link.
Up to this point we have assumed dimensions to be independent of time. While dimension table attributes are relatively static, they are not fixed forever. For example, an Airline may change its name. The approach we took so far is just to overwrite the old value with the new value. In some cases this may be fine. But what if the user one day wants to make a query using the previous name of the airline? In that case we have a problem because the old value is gone.
Another possible area of problems comes along when we get hierarchies in our dimensions.
The typical example here is when you have a Product dimension that rolls up into Product Line. Suppose we have a product X, which belongs to product line A. Now suppose that, because of some organizational change, today we decide that product X will now belong to product line B and we update our Dimension to reflect this. Without slowly changing dimension, now it would seem that product X has ALWAYS belonged to product line B,because we are not keeping track of history. If we asked for the total amount sold for product line B, it would include ALL the sales of product X.
To solve this kind of issue, Slowly Changing Dimensions (SCD) were invented. With these, instead of overwriting the existing value in our Dimension table, we will add a new row to it. This, however, brings up another problem: so far we have used the Airline code (UNIQUE_CARRIER) as unique key in our dimension. But now we might have more than 1 row with the same Airline code.
To solve this, we introduce the concept of the Surrogate Key. This is a sequential and therefore unique number for each row in our Dimension table. So we end up with 2 keys in the Dimension table. The Surrogate key which is truly unique and the Airline code (which from now on we will call the Natural key), which may not be unique.
We have revised the workflow to load the Carrier dimension to be a SCD:

And below you can see what the revised dimension database table would look like. In this (fictional!) example British Airways at some point in time changed its name to New British Airways. As you can see, there are now 2 rows in our dimension table, both have the same natural key (BA), but their surrogate keys are different. Also, the row with the new name has ‘valid’ put to ‘Y’ and the row with the old name has ‘valid’ put to ‘N’. What I did not do in this example, but is considered a best practice, is to add a timestamp column to the dimension table, so we can keep track of just when the change occurred.

Using SCD comes with another implication: we have to change the way our Fact table is loaded, because now we need to use the surrogate key to ‘point’ to the dimension table. This is because the natural key now is no longer always unique, so we could get duplicate records if we joined on it. This also implies that, when updating our data warehouse, we should first update all the dimensions (each thru its own workflow) and lastly the fact table.
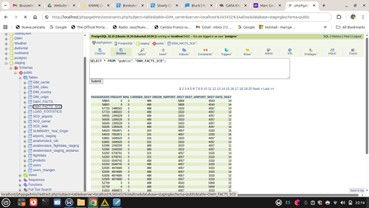
Fact table with Surrogate Keys
Below you can see a picture of our redesigned fact table. We have converted all our dimensions to SCDs and now our fact table contains only surrogate keys and facts:



Comments